As indicated in the introduction above, the basic operation of the HTK training tools involves reading in a set of one or more HMM definitions, and then using speech data to estimate the parameters of these definitions. The speech data files are normally stored in parameterised form such as LPC or MFCC parameters. However, additional parameters such as delta coefficients are normally computed on-the-fly whilst loading each file.
In fact, it is also possible to use waveform data directly by performing the full parameter conversion on-the-fly. Which approach is preferred depends on the available computing resources. The advantages of storing the data already encoded are that the data is more compact in parameterised form and pre-encoding avoids wasting compute time converting the data each time that it is read in. However, if the training data is derived from CD-ROMs and they can be accessed automatically on-line, then the extra compute may be worth the saving in magnetic disk storage.
The methods for configuring speech data input to HTK tools were described in detail in chapter 5. All of the various input mechanisms are supported by the HTK training tools except direct audio input.
The precise way in which the training tools are used depends on the type of HMM system to be built and the form of the available training data. Furthermore, HTK tools are designed to interface cleanly to each other, so a large number of configurations are possible. In practice, however, HMM-based speech recognisers are either whole-word or sub-word.
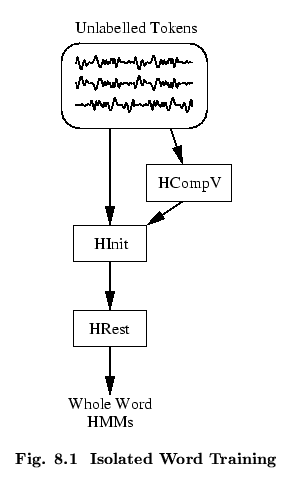
As the name suggests, whole word modelling refers to a technique
whereby each individual word in the system vocabulary is modelled by
a single HMM. As shown in Fig. ![]() , whole word HMMs
are most commonly trained on examples of each word spoken in
isolation. If these training examples, which are often called
tokens, have had leading and trailing silence removed, then
they can be input directly into the training tools without the need
for any label information. The most common method of building whole
word HMMs is to firstly use
HINIT to calculate initial
parameters for the model and then
use
HREST to refine the parameters using Baum-Welch
re-estimation. Where there is limited training data and recognition
in adverse noise environments is needed, so-called fixed
variance models can offer improved robustness. These are models in
which all the variances are set equal to
the global speech variance
and never subsequently re-estimated. The tool
HCOMPV can be used to
compute this global variance.
, whole word HMMs
are most commonly trained on examples of each word spoken in
isolation. If these training examples, which are often called
tokens, have had leading and trailing silence removed, then
they can be input directly into the training tools without the need
for any label information. The most common method of building whole
word HMMs is to firstly use
HINIT to calculate initial
parameters for the model and then
use
HREST to refine the parameters using Baum-Welch
re-estimation. Where there is limited training data and recognition
in adverse noise environments is needed, so-called fixed
variance models can offer improved robustness. These are models in
which all the variances are set equal to
the global speech variance
and never subsequently re-estimated. The tool
HCOMPV can be used to
compute this global variance.
Although HTK gives full support for building whole-word HMM systems, the bulk of its facilities are focused on building sub-word systems in which the basic units are the individual sounds of the language called phones. One HMM is constructed for each such phone and continuous speech is recognised by joining the phones together to make any required vocabulary using a pronunciation dictionary.
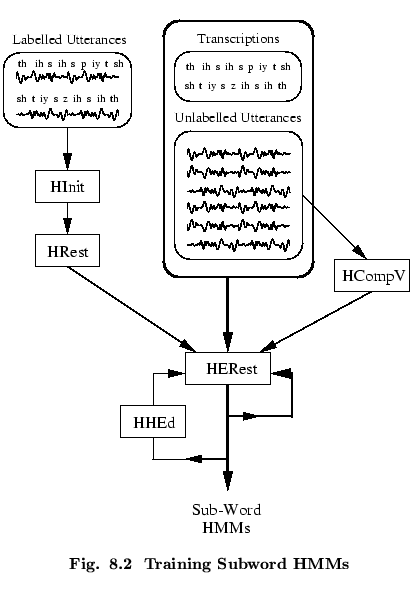
The basic procedures involved in training a set of subword models
are shown in Fig. ![]() . The core process involves the
embedded training tool
HEREST. HEREST uses
continuously spoken utterances as its source of training data
and simultaneously re-estimates the complete set of subword HMMs.
For each input utterance, HEREST needs a transcription i.e. a list of
the phones in that utterance. HEREST then joins together all of the
subword HMMs corresponding to this phone list to make a single
composite HMM. This composite HMM is used to collect
the necessary statistics for the re-estimation. When all of the
training utterances have been processed, the total set of accumulated
statistics are used to re-estimate the parameters of all of the phone
HMMs.
It is important to emphasise that in the above process, the transcriptions
are only needed to identify the sequence of phones in each utterance.
No phone boundary information is needed.
. The core process involves the
embedded training tool
HEREST. HEREST uses
continuously spoken utterances as its source of training data
and simultaneously re-estimates the complete set of subword HMMs.
For each input utterance, HEREST needs a transcription i.e. a list of
the phones in that utterance. HEREST then joins together all of the
subword HMMs corresponding to this phone list to make a single
composite HMM. This composite HMM is used to collect
the necessary statistics for the re-estimation. When all of the
training utterances have been processed, the total set of accumulated
statistics are used to re-estimate the parameters of all of the phone
HMMs.
It is important to emphasise that in the above process, the transcriptions
are only needed to identify the sequence of phones in each utterance.
No phone boundary information is needed.
The initialisation of a
set of phone HMMs prior to embedded re-estimation
using HEREST can be achieved in two different ways. As shown on the
left of Fig. ![]() , a small set of hand-labelled
bootstrap training data can be used along with
the isolated training tools HINIT and HREST to
initialise each phone HMM individually. When used in this way,
both HINIT and HREST use the label information
to extract all the segments of speech corresponding to the current
phone HMM in order to perform isolated word training.
, a small set of hand-labelled
bootstrap training data can be used along with
the isolated training tools HINIT and HREST to
initialise each phone HMM individually. When used in this way,
both HINIT and HREST use the label information
to extract all the segments of speech corresponding to the current
phone HMM in order to perform isolated word training.
A simpler initialisation procedure uses HCOMPV to assign the global speech mean and variance to every Gaussian distribution in every phone HMM. This so-called flat start procedure implies that during the first cycle of embedded re-estimation, each training utterance will be uniformly segmented. The hope then is that enough of the phone models align with actual realisations of that phone so that on the second and subsequent iterations, the models align as intended.
One of the major problems to be faced in building any HMM-based system is that the amount of training data for each model will be variable and is rarely sufficient. To overcome this, HTK allows a variety of sharing mechanisms to be implemented whereby HMM parameters are tied together so that the training data is pooled and more robust estimates result. These tyings, along with a variety of other manipulations, are performed using the HTK HMM editor HHED. The use of HHED is described in a later chapter. Here it is sufficient to note that a phone-based HMM set typically goes through several refinement cycles of editing using HHED followed by parameter re-estimation using HEREST before the final model set is obtained.
Having described in outline the main training strategies, each of the above procedures will be described in more detail.