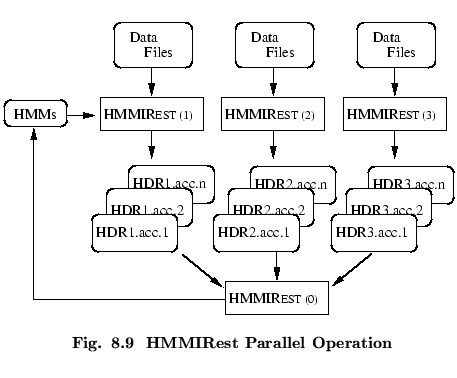
In the same fashion as HEREST, HMMIREST can be run in a
parallel mode. Again, the training data is divided amongst the available
machines and then HMMIREST is run on each machine such that each
invocation of HMMIREST uses the same initial set of models but has its
own private set of data. By setting the option -p N where N is an
integer, HMMIREST will dump the contents of all its
accumulators into a set of files labelled HDRN.acc.1
to HDRN.acc.n. The number of files ![]() depends on the discriminative
training criterion and I-smoothing prior being used. For all set-ups the
denominator and numerator accumulates are kept separate. The standard
training options will have the following number of accumulates:
depends on the discriminative
training criterion and I-smoothing prior being used. For all set-ups the
denominator and numerator accumulates are kept separate. The standard
training options will have the following number of accumulates:
To give a concrete example in the same fashion as described for HEREST, suppose that four networked workstations were available to execute the HMMIREST command performing MMI training. Again the training files listed previously in trainlist would be split into four equal sets and a list of the files in each set stored in trlist1, trlist2, trlist3, and trlist4. Phone-marked numerator and denominator lattices are assumed to be available in plat.num and plat.den respectively. On the first workstation, the command
HMMIRest -S trlist1 -C mmi.cfg -q plat.num -r plat.den\
-H dir1/hmacs -M dir2 -p 1 hmmlist
would be executed. This will load in the HMM definitions in
dir1/hmacs, process the files listed in trlist1 and finally
dump its accumulators into files called HDR1.acc.1 and HDR1.acc.2 in the output
directory dir2. At the same time, the command
HMMIRest -S trlist2 -C mmi.cfg -q plat.num -r plat.den\
-H dir1/hmacs -M dir2 -p 2 hmmlist
would be executed on the second workstation, and so on. When
HMMIREST has finished on all four
workstations, the following command will be executed on just one of them
HMMIRest -C mmi.cfg -H dir1/hmacs -M dir2 -p 0 hmmlist \
dir2/HDR1.acc.1 dir2/HDR1.acc.2 dir2/HDR2.acc.1 dir2/HDR2.acc.2 \
dir2/HDR3.acc.1 dir2/HDR3.acc.2 dir2/HDR4.acc.1 dir2/HDR4.acc.2
where the list of training files has been replaced by the dumped accumulator
files. This will cause the accumulated
statistics to be reloaded and merged so that the model parameters can
be reestimated and the new model set output to dir2
When discriminatively training large systems on large amounts of training data, and to a lesser extent for maximum likelihood training, the merging of possibly hundreds of accumulators associated with large model sets can be slow and significantly load the network. To avoid this problem, it is possible to merge subsets of the accumlators using the UPDATEMODE = DUMP configuration option. As an example using the above configuration, assume that the file dump.cfg contains
UPDATEMODE = DUMPThe following two commands would be used to merge the statistics into two sets of accumulators in directories acc1 and acc2.
HMMIRest -C mmi.cfg -C dump.cfg -H dir1/hmacs -M acc1 -p 0 hmmlist \
dir2/HDR1.acc.1 dir2/HDR1.acc.2 dir2/HDR2.acc.1 dir2/HDR2.acc.2
HMMIRest -C mmi.cfg -C dump.cfg -H dir1/hmacs -M acc2 -p 0 hmmlist \
dir2/HDR3.acc.1 dir2/HDR3.acc.2 dir2/HDR4.acc.1 dir2/HDR4.acc.2
These two sets of merged statistics can then be used to update the acoustic
model using
HMMIRest -C mmi.cfg -H dir1/hmacs -M dir2 -p 0 hmmlist \
acc1/HDR0.acc.1 acc1/HDR0.acc.2 acc2/HDR0.acc.1 acc2/HDR0.acc.2
For very large systems this hierarchical merging of stats can be done
repeatedly. Note this form of accumulate merger is also supported for
HEREST.