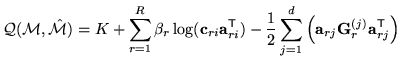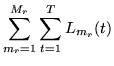Variance Transformation Matrix (MLLRVAR, MLLRCOV)
Estimation of the first variance transformation matrices is only available
for diagonal covariance Gaussian systems in the current implementation,
though full transforms can in theory be estimated. The Gaussian covariance is
transformed using9.5,
where
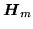 is the linear transformation to be estimated and
is the linear transformation to be estimated and
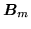 is the inverse of the Choleski factor of
is the inverse of the Choleski factor of
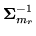 ,
so
and
After rewriting the auxiliary function, the transform matrix
is estimated from,
Here,
,
so
and
After rewriting the auxiliary function, the transform matrix
is estimated from,
Here,
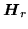 is forced to be a diagonal transformation by setting
the off-diagonal terms to zero, which ensures that
is forced to be a diagonal transformation by setting
the off-diagonal terms to zero, which ensures that
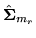 is also diagonal.
is also diagonal.
The alternative form of variance adaptation us supported for full,
block and diagonal transforms. Substituting the for expressions for
variance adaptation
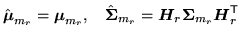 |
|
|
(9.13) |
into the auxiliary function, and using the fact that the covariance
matrices are diagonal yields
where
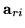 is
is 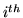 row of
row of
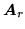 , the
, the 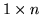 row vector
row vector
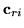 is the vector of
cofactors of
,
is the vector of
cofactors of
,
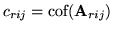 ,
and
,
and
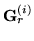 is defined as
is defined as
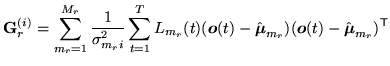 |
|
|
(9.16) |
Differentiating the auxiliary function with respect to the transform
, and then maximising it with respect to the transformed mean
yields the following update
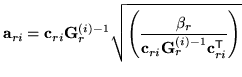 |
|
|
(9.17) |
This is an iterative optimisation scheme as the cofactors mean the estimate
of row 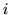 is dependent on all the other rows (in that block). For the
diagonal transform case it is of course non-iterative and simplifies to
the same form as the MLLRVAR transform.
is dependent on all the other rows (in that block). For the
diagonal transform case it is of course non-iterative and simplifies to
the same form as the MLLRVAR transform.
Back to HTK site
See front page for HTK Authors
![$\displaystyle {\mbox{\boldmath$H$}}_r = \frac{ \sum_{m_r=1}^{M_r}{\mbox{\boldma...
..._{m_r})^{\scriptstyle\sf T}\right]
{\mbox{\boldmath$C$}}_{m_r} } { L_{m_r}(t)}
$](img464.png)