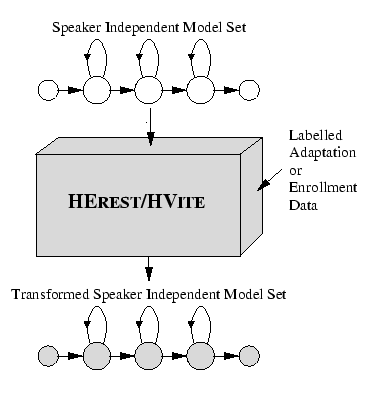
Chapter 8 described how the parameters are estimated for plain continuous density HMMs within HTK, primarily using the embedded training tool HEREST. Using the training strategy depicted in figure 8.2, together with other techniques can produce high performance speaker independent acoustic models for a large vocabulary recognition system. However it is possible to build improved acoustic models by tailoring a model set to a specific speaker. By collecting data from a speaker and training a model set on this speaker's data alone, the speaker's characteristics can be modelled more accurately. Such systems are commonly known as speaker dependent systems, and on a typical word recognition task, may have half the errors of a speaker independent system. The drawback of speaker dependent systems is that a large amount of data (typically hours) must be collected in order to obtain sufficient model accuracy.
Rather than training speaker dependent models, adaptation techniques can be applied. In this case, by using only a small amount of data from a new speaker, a good speaker independent system model set can be adapted to better fit the characteristics of this new speaker.
Speaker adaptation techniques can be used in various different modes. If the true transcription of the adaptation data is known then it is termed supervised adaptation, whereas if the adaptation data is unlabelled then it is termed unsupervised adaptation. In the case where all the adaptation data is available in one block, e.g. from a speaker enrollment session, then this termed static adaptation. Alternatively adaptation can proceed incrementally as adaptation data becomes available, and this is termed incremental adaptation.
HTK provides two tools to adapt continuous density HMMs. HEREST performs offline supervised adaptation using various forms of linear transformation and/or maximum a-posteriori (MAP) adaptation, while unsupervised adaptation is supported by HVITE (using only linear transformations). In this case HVITE not only performs recognition, but simultaneously adapts the model set as the data becomes available through recognition. Currently, linear transformation adaptation can be applied in both incremental and static modes while MAP supports only static adaptation.
This chapter describes the operation of supervised adaptation with the HEREST tools. The first sections of the chapter give an overview of linear transformation schemes and MAP adaptation and this is followed by a section describing the general usages of HEREST to build simple and more complex adapted systems. The chapter concludes with a section detailing the various formulae used by the adaptation tool. The use of HVITE to perform unsupervised adaptation is described in the RM Demo.