Robust model estimation
Given a suitably large amount of training data, an extremely long 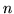 -gram
could be trained to give a very good model of language, as per equation
14.1 - in practice, however,
any actual extant model must be an approximation. Because it is an
approximation, it will be detrimental to include within the model
information which in fact was just noise introduced by the limits of
the bounded sample set used to train the model - this information may
not accurately represent text not contained within the training
corpus. In the same way, word sequences which were not observed in the
training text cannot be assumed to represent impossible sequences, so
some probability mass must be reserved for these. The issue of how to
redistribute the probability mass, as assigned by the maximum likelihood
estimates derived from the raw statistics of a specific corpus, into a
sensible estimate of the real world is addressed by various standard
methods, all of which aim to create more robust language models.
-gram
could be trained to give a very good model of language, as per equation
14.1 - in practice, however,
any actual extant model must be an approximation. Because it is an
approximation, it will be detrimental to include within the model
information which in fact was just noise introduced by the limits of
the bounded sample set used to train the model - this information may
not accurately represent text not contained within the training
corpus. In the same way, word sequences which were not observed in the
training text cannot be assumed to represent impossible sequences, so
some probability mass must be reserved for these. The issue of how to
redistribute the probability mass, as assigned by the maximum likelihood
estimates derived from the raw statistics of a specific corpus, into a
sensible estimate of the real world is addressed by various standard
methods, all of which aim to create more robust language models.
Subsections
Back to HTK site
See front page for HTK Authors