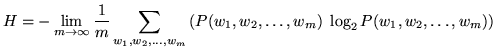 |
(14.20) |
This summation is over all possible sequences of words, but if the source is ergodic then the summation over all possible word sequences can be discarded and the equation becomes equivalent to:
| (14.21) |
Having assumed this ergodic property, it follows that given a large
enough value of ![]() ,
, ![]() can be approximated with:
can be approximated with:
Considering a language model as an information source, it follows that
a language model which took advantage of all possible features of
language to predict words would also achieve a per-word entropy of
![]() . It therefore makes sense to use a measure related to entropy to
assess the actual performance of a language model. Perplexity,
. It therefore makes sense to use a measure related to entropy to
assess the actual performance of a language model. Perplexity, ![]() ,
is one such measure that is in standard use, defined such that:
,
is one such measure that is in standard use, defined such that:
Perplexity can be considered to be a measure of on average how many different equally most probable words can follow any given word. Lower perplexities represent better language models, although this simply means that they `model language better', rather than necessarily work better in speech recognition systems - perplexity is only loosely correlated with performance in a speech recognition system since it has no ability to note the relevance of acoustically similar or dissimilar words.
In order to calculate perplexity both a language model and some test text are required, so a meaningful comparison between two language models on the basis of perplexity requires the same test text and word vocabulary set to have been used in both cases. The size of the vocabulary can easily be seen to be relevant because as its cardinality is reduced so the number of possible words given any history must monotonically decrease, therefore the probability estimates must on average increase and so the perplexity will decrease.