Overview of
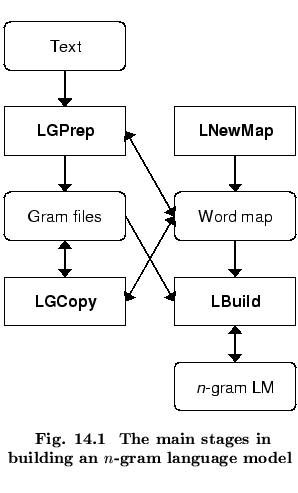
The overall process involved in building an ![]() -gram language model
using the HTK tools is illustrated in Figure 14.1. The
procedure begins with some training text, which first of all should be
conditioned into a suitable format by performing operations such as
converting numbers to a citation form, expanding common abbreviations
and so on. The precise format of the training text depends on your
requirements, however, and can vary enormously - therefore
conditioning tools are not supplied with HTK.14.17
-gram language model
using the HTK tools is illustrated in Figure 14.1. The
procedure begins with some training text, which first of all should be
conditioned into a suitable format by performing operations such as
converting numbers to a citation form, expanding common abbreviations
and so on. The precise format of the training text depends on your
requirements, however, and can vary enormously - therefore
conditioning tools are not supplied with HTK.14.17
Given some input text, the tool LGPREP scans the input word
sequence and counts ![]() -grams.14.18 These
-grams.14.18 These ![]() -gram counts
are stored in a buffer which fills as each new
-gram counts
are stored in a buffer which fills as each new ![]() -gram is
encountered. When this buffer becomes full, the
-gram is
encountered. When this buffer becomes full, the ![]() -grams within it
are sorted and stored in a gram file.
All words (and symbols generally) are represented within HTK by a
unique integer id. The mapping from words to ids is recorded in a
word map. On startup, LGPREP loads in an existing word map,
then each new word encountered in the input text is allocated a new id
and added to the map. On completion, LGPREP outputs the new
updated word map. If more text is input, this process is repeated and
hence the word map will expand as more and more data is processed.
-grams within it
are sorted and stored in a gram file.
All words (and symbols generally) are represented within HTK by a
unique integer id. The mapping from words to ids is recorded in a
word map. On startup, LGPREP loads in an existing word map,
then each new word encountered in the input text is allocated a new id
and added to the map. On completion, LGPREP outputs the new
updated word map. If more text is input, this process is repeated and
hence the word map will expand as more and more data is processed.
Although each of the gram files output by LGPREP is sorted,
the range of ![]() -grams within individual files will overlap. To build
a language model, all
-grams within individual files will overlap. To build
a language model, all ![]() -gram counts must be input in sort order so
that words with equivalent histories can be grouped. To accommodate
this, all HTK language modelling tools can read multiple gram files
and sort them on-the-fly. This can be inefficient, however, and it is
therefore useful to first copy a newly generated set of gram files
using the HLM tool LGCOPY. This yields a set of gram files
which are sequenced, i.e. the ranges of
-gram counts must be input in sort order so
that words with equivalent histories can be grouped. To accommodate
this, all HTK language modelling tools can read multiple gram files
and sort them on-the-fly. This can be inefficient, however, and it is
therefore useful to first copy a newly generated set of gram files
using the HLM tool LGCOPY. This yields a set of gram files
which are sequenced, i.e. the ranges of ![]() -grams within each
gram file do not overlap and can therefore be read in a single stream.
Furthermore, the sequenced files will take less disc space since the
counts for identical
-grams within each
gram file do not overlap and can therefore be read in a single stream.
Furthermore, the sequenced files will take less disc space since the
counts for identical ![]() -gram in different files will have been
merged.
-gram in different files will have been
merged.
The set of (possibly sequenced) gram files and their associated word
map provide the raw data for building an ![]() -gram LM. The next stage
in the construction process is to define the vocabulary of the LM and
convert all
-gram LM. The next stage
in the construction process is to define the vocabulary of the LM and
convert all ![]() -grams which contain OOV (out of vocabulary) words so
that each OOV word is replaced by a single symbol representing the
unknown class. For example, the
-grams which contain OOV (out of vocabulary) words so
that each OOV word is replaced by a single symbol representing the
unknown class. For example, the ![]() -gram AN OLEAGINOUS
AFFAIR would be converted to AN !!UNK AFFAIR if the word
``oleaginous'' was not in the selected vocabulary and !!UNK
is the name chosen for the unknown class.
-gram AN OLEAGINOUS
AFFAIR would be converted to AN !!UNK AFFAIR if the word
``oleaginous'' was not in the selected vocabulary and !!UNK
is the name chosen for the unknown class.
This assignment of OOV words to a class of unknown words is a specific example of a more general mechanism. In HTK, any word can be associated with a named class by listing it in a class map file. Classes can be defined either by listing the class members or by listing all non-members. For defining the unknown class the latter is used, so a plain text list of all in-vocabulary words is supplied and all other words are mapped to the OOV class. The tool LGCOPY can use a class map to make a copy of a set of gram files in which all words listed in the class map are replaced by the class name, and also output a word map which contains only the required vocabulary words and their ids plus any classes and their ids.
As shown in Figure 14.1, the LM itself is built using the tool LBUILD. This takes as input the gram files and the word map and generates the required LM. The language model can be built in steps (first a unigram, then a bigram, then a trigram, etc.) or in a single pass if required.