|
|||||||||
Overview of Feedback-related Research |
|
“Can you send me some papers about feedback?”, a newcomer to the research group might ask. Other common questions related to our research are “What is incremental redundancy?”, “What do you mean by punctured codes?”, and “How does this relate to finite-blocklength information theory?”
This page attempts to answer those questions and provide an overview of the classic and recent literature related to our feedback research efforts. “Feedback” in this context spans several areas of communications, coding, and information theory. Please contact the webmaster if you have suggestions for recommended additions to this page. ContentsPuncturing (and Rate-compatible Puncturing)Incremental Redundancy Hybrid ARQ Finite-blocklength Information Theory Low-latency Coding Reliability-based Decoding Algorithms What Kind of Feedback? Puncturing (and Rate-compatible Puncturing)A classic paper that illustrates the puncturing concept is by Hagenauer in 1988. In punctured codes, a low-rate codeword of N symbols is generated by the encoder, but only a portion of the coded symbols are transmitted. The missing symbols are called “punctured”, and the receiver decodes without the full codeword.
More germane to our research are rate-compatible punctured codes, which is a family of punctured codes with various rates. In rate-compatible codes, all code bits of a high-rate code are also used by the lower-rate codes. These codes are suitable for use in an incremental redundancy scheme. |
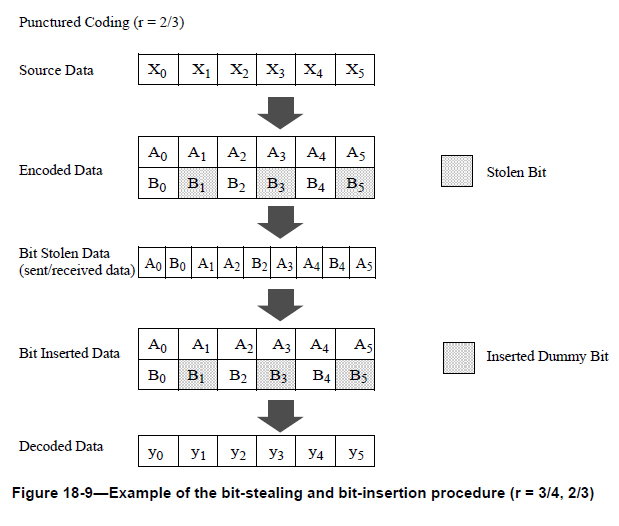
|
The figure above shows an example of the puncturing matrix used in the IEEE 802.11 wireless standard. Rate 1/2 mother codes are punctured to generate rate 2/3 codes.
Incremental RedundancyIn Automatic Repeat reQuest (ARQ) schemes, the receiver uses feedback to tell the transmitter whether it has decoded correctly (often called an ACK for acknowledgement) or not (negative acknowledgement, or NACK). The transmitter will then repeat by sending the same block over again. This continues until the receiver has decoded successfully.First used by Mandelbaum in 1974, the term incremental redundancy refers to a decision–feedback scheme in which the transmitter only has to send additional coded increments after the receiver fails to decode, instead of sending the entire block. After each transmission, the receiver will attempt to decode with all the received blocks, not just the last increments. With rate-compatible codes, a single encoder can be used to generate a sequence of high-rate to low-rate codewords.
|
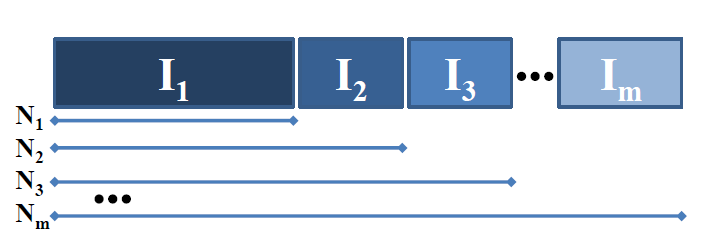
|
|
There are many papers discussing incremental redundancy schemes, both in the communications and information theory literature, including several papers from our group. A good starting point is the following paper by Williamson, Chen, and Wesel, which provides equations for computing the average throughput (coding rate) and latency (blocklength) of incremental redundancy systems.
Hybrid ARQThe original instances of ARQ systems transmitted uncoded data bits along with parity bits from an error-detection code, such as a cyclic redundancy check (CRC). The ACK/NACK requests from the receiver were determined by the result of the CRC. Later, error-correction codes (also called forward error-correction) were used to in order to communicate more reliably. The combination of ARQ error-control and error-correction codes became known as hybrid ARQ (HARQ).A good reference for hybrid ARQ and incremental redundancy is the work of Emina Soljanin at Bell Labs, whose research includes LDPC and Raptor codes in the context of HARQ:
The following paper also describes the different types of hybrid ARQ:
Finite-blocklength Information TheoryShannon showed in 1956 that noiseless feedback does not increase the capacity of memoryless channels, at least when the blocklength of a code is allowed to go to infinity. That is, asymptotically, the capacity is the same regardless of whether feedback is used.
Shannon’s asymptotic definition of a channel’s capacity may seem problematic (since no code used in the real world can have an infinite length!), yet this definition of channel capacity has proved extremely useful in the real world. It has helped researchers design error-correcting codes and measure their performance relative to the maximum coding rate (the capacity). Still, even in the 1960s, Shannon and his contemporaries investigated the finite-length performance of codes, evaluating the achievable rates and error probabilities of codes with practical lengths. Activity in this field diminished over time, but a seminal paper of Polyanskiy, Poor, and Verdú in 2010 quickly sparked a resurgence in this area. Polyanskiy et al. provided new bounds on the maximum rate achievable at fixed blocklengths and error probabilities. Their work was focused on point-to-point, static channels, though other researchers have extended their ideas to analyze multi-user channels and fading channels.
|
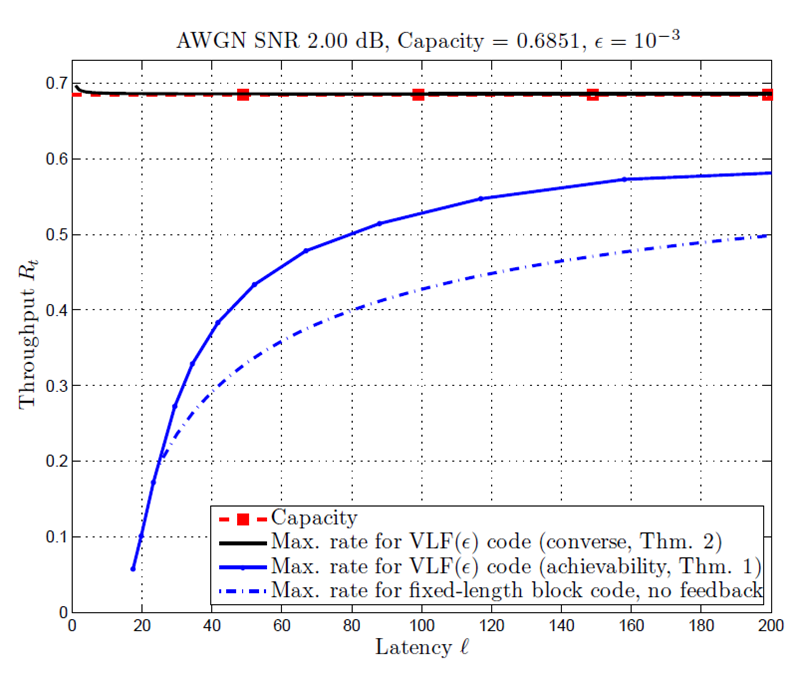
|
They coined the term variable-length feedback (VLF) codes to describe a transmission scheme in which the receiver can decide to stop decoding after any received symbol. In this framework, the length of the code is not fixed but a random variable, and the rate is computed by taking an expectation over the random stopping time. The figure below shows the upper (converse) and lower (achievability) bounds on rate for VLF codes on the AWGN channel. The no-feedback curve uses Polyanskiy, Poor, and Verdú's normal approximation, which is based on the channel dispersion. |
In this light, incremental redundancy schemes (hybrid ARQ) are a special case of VLF codes. Instead of being able to stop transmission after any received symbol, however, hybrid ARQ systems in practice limit decoding to one of several possible blocklengths. As a result, the VLF results of Polyanskiy, Poor, and Verdú provide a helpful information-theoretic benchmark to see how well incremental redundancy schemes perform in the short-blocklength regime. Chen, Williamson, and Wesel have extended the VLF analysis of Polyanskiy et al. to include practical limitations on decoding lengths.
Low-latency CodingConvolutional codes are not capacity-approaching, unlike turbo codes and LDPC codes. However, their performance at short blocklengths can often surpass that of capacity-approaching codes. This benefit motivated our use of punctured convolutional codes in feedback systems.Recent research has also compared the short-blocklength performance of convolutional codes (with maximum-likelihood, Viterbi decoding) to LDPC codes (with iterative message-passing decoding) and convolutional codes (with stack sequential decoding). Maiya, Costello, and Fuja found that for a fixed target error-rate (e.g., BER = 10-6) and code rate (e.g., Rc = 1/2 ), Viterbi-decoded convolutional codes offered the best performance at low latency (e.g., less than 100 bits) and that LDPC codes decoded with iterative message passing offered the best performance for high latencies (e.g., greater than 220 bits). In an intermediate range of latencies (e.g., 100 to 220 bits), convolutional codes with stack sequential decoding were optimal.
Reliability-based Decoding AlgorithmsIn order for the receiver in a feedback-based retransmission scheme to request additional symbols, the receiver must decide whether the received word is reliable. Two common methods are CRCs, also called the code-based approach, and reliability-based decoding.CRCs are commonly used to detect errors in modern wired and wireless communications systems. If the check bits computed by the decoder do not match the received check bits, additional symbols are requested. However, undetected errors can occur when the check bits erroneously match. For more information about choosing the appropriate CRC polynomials (and to see how some CRCs in standards are not optimal), consult the excellent work of Koopman at Carnegie Mellon:
|
Many reliability-based decoding algorithms have been designed for convolutional codes that take advantage of the trellis structure, which makes the complexity manageable. Two salient examples are the Yamamoto-Itoh algorithm and Raghavan and Baum’s reliability-output Viterbi algorithm (ROVA). The ROVA computes the exact word-error probability of a a decoded word given the received sequence, 1 – P(x|y). The Yamamoto-Itoh algorithm does not compute the exact word-error probability, but similarly determines whether the surviving path in a Viterbi decoder is sufficiently reliable, based on a reliability parameter.
|
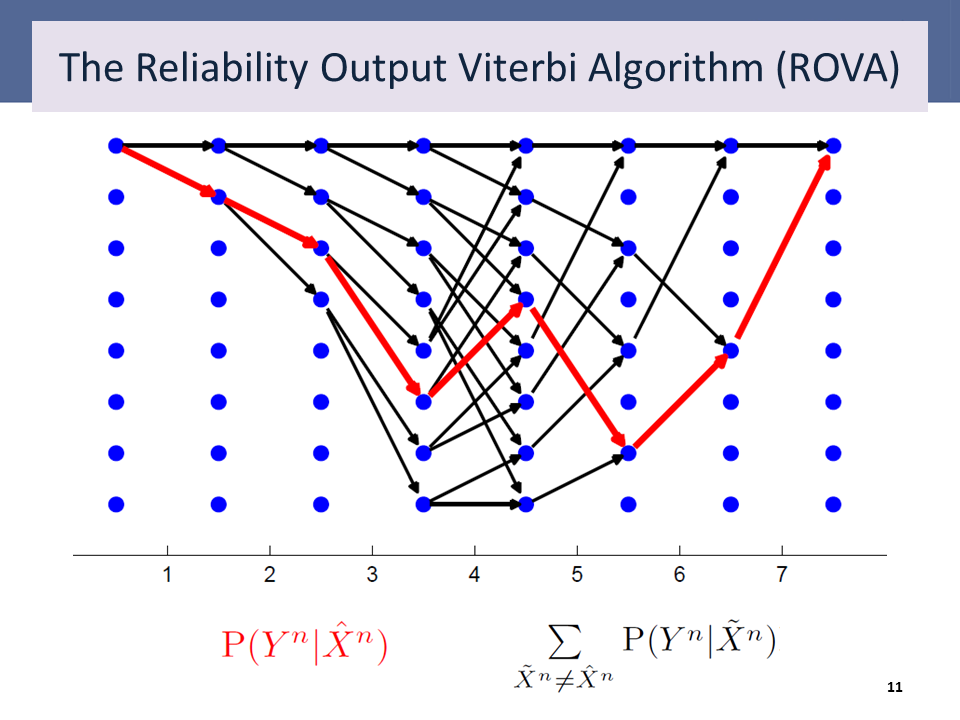
|
Both of these algorithms have been used in a number of repeat request schemes (that is, ARQ or HARQ). Fricke and Hoeher compared the throughputs of the reliability-based error detection approach using the ROVA and the code-based approach using CRCs.
What Kind of Feedback?Our research assumes that noiseless feedback is sent from the receiver to the transmitter after each forward channel use. The variable-length feedback coding framework of Polyanskiy, Poor, and Verdú allows for a full-precision version of the nth received symbol y_n to be fed back, which the transmitter may use to select the subsequent transmitted symbol x_{n+1}.In many practical cases, however, feedback is only used to inform the transmitter whether the receiver has finished decoding (ACK) or needs additional symbols (NACK). Polyanskiy, Poor, and Verdú refer to this as a stop-feedback code, since feedback is used by the transmitter to learn when the receiver stops. Forney calls this decision feedback, indicating that the receiver sends back its decision, but not the received symbols. In these cases, only 1 bit of feedback (still noiseless) is required. While in practice no transmissions can be entirely noise-free, the noiseless assumption seems reasonable, since the 1 bit could be sufficiently protected with a low-rate code. In contrast, Forney refers to systems in which the receiver sends back the received symbols as information feedback. This paradigm allows the transmitter to adapt its future coded symbols based on the information received so far. Recent work by Naghshvar and Javidi generalizes this setup as active, sequential hypothesis-testing, of which channel coding is just one example. The variable-length aspect of feedback coding explains the “sequential” descriptor, and “active” indicates that the codebook is not generated before message transmission, but that coded symbols are generated progressively, as a result of the feedback messages.
There are opportunities to use the ideas of active feedback for short-blocklength codes, as well. In the following paper, Williamson, Chen, and Wesel constructed a two-phase scheme that uses feedback to confirm or deny the receiver's tentative estimate. We showed that this communication and confirmation scheme, inspired by the classical error-exponent papers, could beat the random-coding lower bound for VLF codes. We used convolutional codes in the communication phase and repetition codes in the confirmation phase.
|
Files (top)
|
| This material is based upon work supported by the National Science Foundation under Grant Number 1162501. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. |
| Copyright@2007-2013 UCLA CSL |